This blog post accompanies Semantics of Empire: A Neural Machine Translation Approach for Ottoman Turkish, which brings the power of recent technological breakthroughs in artificial intelligence (AI) and neural machine translation (NMT) to Ottoman Turkish. I am training a translator for my Symbolic Systems M.S. project at Stanford University. By the end of this project, I intend to release Semantics of Empire as a first pass translator and host it freely for all scholars and researchers in the Ottoman Empire and Middle Eastern Studies fields.
Project
My project consists of two components, training an NMT model that can act as a first-pass translator for Ottoman Turkish, and testing the performance of OpenAI’s Generative Pre-Trained Transformer model, GPT-4. Released in February 2023, GPT-4 showed what some AI and natural language processing (NLP) researchers call emergent capabilities. In my research, emergent capabilities refers to Large Language Models (LLMs) like GPT-4 demonstrating surprisingly high performance in natural language tasks for which they were not explicitly trained. One such task is translation of Ottoman Turkish into English.
Machine Translation and GPT-4
In the domain of NLP, machine translation (MT) is a task that requires parallel data. Practically, this means that MT datasets consist of sentences in source and target languages that are translations of one another. NMT model training differs from that of GPT-4, because translation is a sequence-to-sequence task. In NMT, the source sentence is encoded and the target sentence is decoded, which means that the model generates the source sentence in the target language. GPT-4, on the other hand, is an autoregressive model. In simplified terms, GPT-4 generates a sentence by decoding it word by word.
To the best of our knowledge, GPT-4 has never been trained specifically for translation, let alone for the translation of Ottoman Turkish. While the details about the training data and implementation are proprietary information that OpenAI has not publicly disclosed, it is safe to assume that GPT-4 has not been explicitly trained on Ottoman Turkish texts. However, GPT-4 probably encountered Ottoman texts as part of its training since it has seen all of the Internet in some fashion.
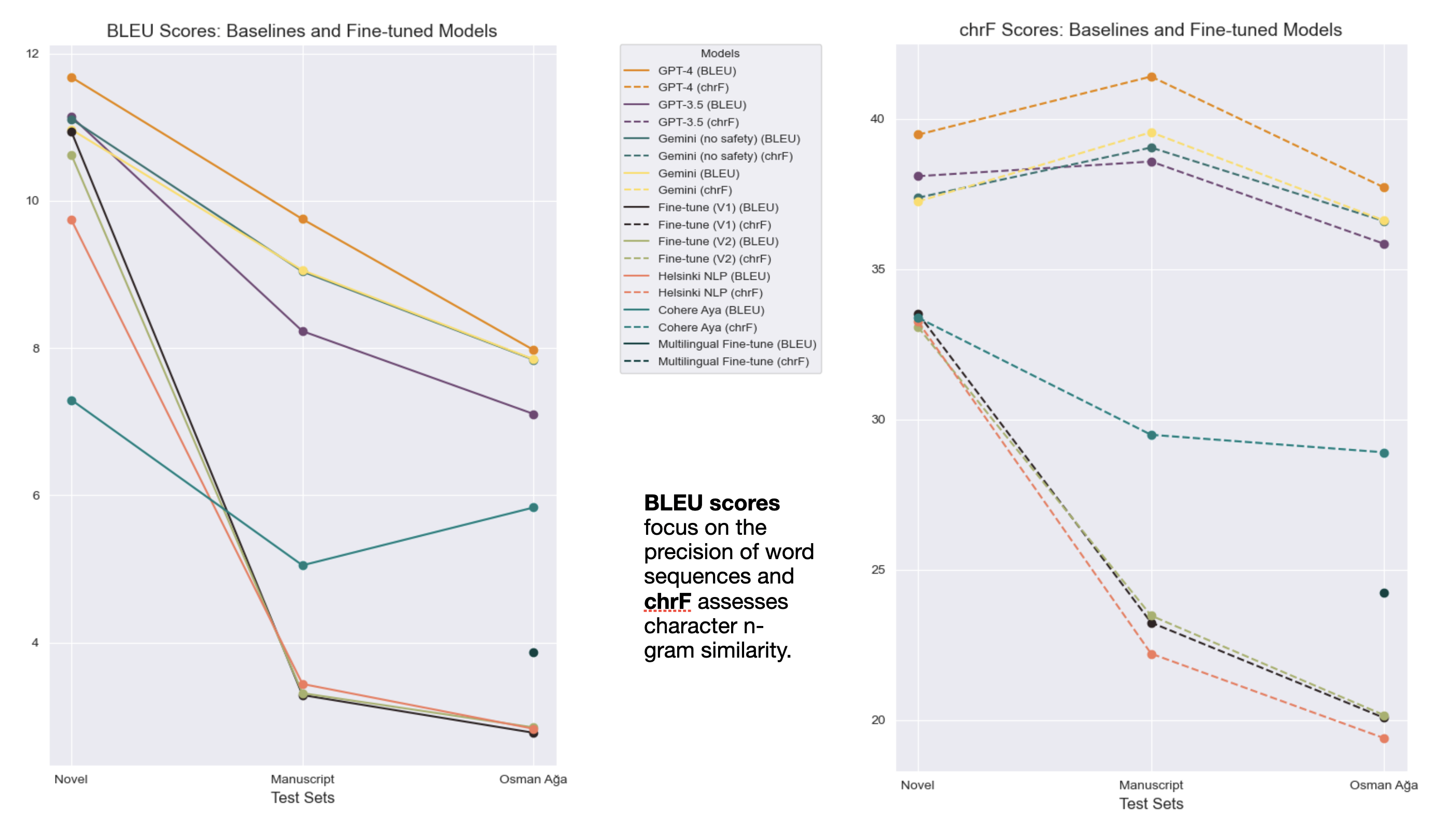
Despite the gaps of knowledge surrounding the ‘how’ and the ‘why,’ I established empirically through Semantics of Empire that GPT-4 outperforms other LLMs and NMT models trained for Modern Turkish to English translation. Below is a chart comparing the performance of several models–including some that I fine-tuned–on three test texts: an Ottoman novel, Ahmet Mithat Efendi’s Felâtun Bey ve Râkim Efendi, a late 18th century manuscript Hulasatü’l-itibar by Ahmed Resmi, and an early 18th century manuscript, Osman Ağa’s account of his imprisonment.
Experiment
I was initially surprised by GPT-4’s performance; the model-translated texts looked similar to scholarly translations. These initial findings encouraged me to test GPT-4’s performance more methodologically. I designed the following experiment, which will be a part of my M.S. thesis in Symbolic Systems, supervised by Prof Mark Algee-Hewitt, and more broadly a component of my History dissertation, advised by Prof Ali Yaycıoğlu. This experiment is conducted fully online through a website that I built: Ottoman Translator
My website uses the OpenAI GPT-4 API to query the model to translate Ottoman Turkish sentences submitted by you, the experiment participants. Upon typing or pasting a sentence in the text box, you click the ‘Translate’ button. The English translation of the sentence will appear under the text box. After reading the translation, click the ‘Edit This Translation’ button to offer corrections. A pop up will appear with the sentence translated by the model. You are asked to edit or correct the translated sentence based on your domain knowledge and expertise.
Guidelines for Using the Translation Tool
- Do not input sentences that are too long, i.e. over 70-80 words, depending on the character length of your words. The model performance decreases drastically with longer texts. This limitation stems from the model’s architecture.
- Do not click the Translate button repeatedly. It might take up to 30 seconds for the translation to appear. If there is an issue, you will see an error message pop up immediately.
- Crucially, don’t forget to offer edits and corrections to the translated sentences. Each translation costs me some amount of money for which I have very limited funds. As a graduate student, I need to collect data for research purposes and do not have the means to offer this as a free service. I appreciate your understanding and collaboration in this regard.
- Note that the translations may not be fully accurate. They are not scholarly translations. Always read and carefully evaluate them.
- You may use the translations that you generate on my website for research and teaching purposes. If you do so, cite my work with the instructions provided at the very end of this blog post.
Data Usage
I use the Google Sheets API to collect your input, the model’s translation, and your correction. I am not collecting any identifying information including, but not limited to, IP addresses. My experiment does not fall under the domain of Stanford University’s Institutional Review Board (IRB) because I am testing model performance with human annotators, which does not constitute a human experiment. Throughout Summer 2024, I will use the data generated in my experiment to test GPT-4’s performance on a set of Ottoman Turkish examples from a broader time period than my PhD research focus. I will also incorporate this data into my model training.
Future Directions
Ultimately, my goal is to produce a model that can compete with GPT-4 as a first pass translator and host it freely for all scholars and researchers in the Ottoman Empire and Middle Eastern Studies fields. This is why at this point in time I am inviting scholars of Ottoman Turkish to participate in this experiment and help me build the digital future for our field. All comments and questions can be directed to me via email.
Citations
If you use translations from this model in your scholarship, or engage with this project in any other way, please cite this post as you would with any publication. You may use this format for citations: Merve Tekgürler. Experimenting with GPT-4 for Machine Translation from Ottoman Turkish into English. First Published: 05/01/2024. URL: https://github.com/mervetekgurler/mervetekgurler.github.io/blob/7ad5adcc1271396ce2fa08803c156ce4d10ebd9f/_posts/2024-05-01-GPT4-translator.md